Tillinger Gábor: A számi idiómák és a dialektometria
A számi idiómák[1] és a dialektometria
- A számi nyelvváltozatok és azok csoportosítása
Kilenc főbb számi idiómát szokás megkülönböztetni (déli, umei, pitei, lulei, északi, inari, kolta, kildini, teri), ezeket hívják sokszor számi nyelveknek. Sápmi, azaz Számiföld, ahol a különböző számi nyelvváltozatokat (a feltételezett 80–100 ezer fő számiból) összesen 30–40 ezren beszélik, meglehetősen nagy kiterjedésű, kb. 400–450 ezer km – nagyobb tehát, mint Finnország vagy Németország, és majdnem akkora, mint Svédország vagy Spanyolország. Ezt a kilenc idiómát nyelvészek rendszeresen csoportosítgatni szokták, ahol is a csoportok hivatottak tükrözni az idiómák egymáshoz viszonyított hasonlóságát, azaz a köztük tapasztalható nyelvi távolságokat. Ami felettébb érdekes, az az, hogy több, egymástól eltérő csoportosítással találkozhatunk a szakirodalomban. Joggal merül fel hát a kérdés, hogy mit is tükröznek ezek a csoportosítások, ha ennyire különbözőek.
Knut Bergsland (1968) egyértelművé tette, hogy mindegy, hogyan kategorizáljuk a nyelvváltozatokat, mindig is több lehetséges és elfogadható csoportosítás lesz, annak függvényében, hogy milyen nyelvi sajátosságokat, egyezéseket, különbségeket, izoglosszákat akarunk előtérbe helyezni a fiktív határvonalak meghúzásakor. Bergsland ugyanakkor úgy vélte, hogy ha szeretnénk kialakítani egy összegző csoportosítást a számi idiómákra nézve, akkor a határt két nagy csoport (egy nyugati és egy keleti) között a lulei és az északi számi közt kell meghúznunk, és nem az északi és az inari számi között (Bergsland 1946: VIII). Ezen véleményét nagyon sokáig szinte egyik számi idiómákkal foglalkozó tudós sem osztotta.
Mikko Korhonen (1981: 3–5) is több lehetséges csoportosítást vázolt, de van egy közös pont ezekben: az északi és az inari számi között mindig markáns vonalat húzott, ezt a két idiómát két különböző csoportba helyezve. Korhonen szerint vagy két csoportot állítunk fel – egy nyugatit (déli, umei, pitei, lulei, északi) és egy keletit (inari, kolta, akkalai[2], kildini, teri) –, vagy esetleg elképzelhető még egy hármas felosztás – déli csoport (déli, umei), centrális csoport (pitei, lulei, északi), keleti csoport (inari, kolta, akkalai, kildini, teri). A Korhonennél szereplő hármas felosztást korábban Björn Collinder (1953: 64) is bemutatta már.
Jocelyne Fernandez-Vest (1997: 12) egy még osztottabb képet vázol – amelyet mellesleg „tradicionális” felosztásnak titulál –, ám az északi és az inari közti választóvonal ismét látványos. Fernandez-Vest szerint négy csoportba sorolhatjuk a számi idiómákat, a következőképpen: déli csoport (déli), centrális csoport (umei, pitei, lulei), északi csoport (északi), keleti (inari, kolta, kildini, teri).
Pekka Sammallahti munkáiban szintén választóvonalat találhatunk az északi és az inari számi között. Sammallahti (1998: 6) két csoportot feltételez, egy nyugatit (déli, umei, pitei, lulei, északi) és egy keletit (inari, kolta, akkalai, kildini, teri) – ezen felosztás Korhonen egyik csoportosításával vág egybe.
Az északi számi és az inari számi között feltételezett éles határvonalról egyébként már 1906-ban említést tett Frans Äimä (Rydving 2013: 53).
Ezen esetek mindegyikében a csoportosítások főleg a fonológiai és morfológiai eltéréseken alapulnak, és elsődlegesen a nyelvtörténeti változásokat tükrözik. Felmerül azonban a kérdés, hogy mennyiben tükrözik e különbségek az idiómák „egésze” közti távolságokat, például ha a kölcsönös érthetőségre gondolunk.
Ha az északi germán nyelveket vesszük példaként, a dán és a svéd egy csoportban, az ún. keleti csoportban van, míg a norvég[3] egy másikban, az ún. nyugatiban (Barðdal et al. 1997: 24; Bussmann 2002: 251). A kölcsönös érthetőségre vonatkozó kutatások eredményei azonban azt mutatják, hogy a norvég és a svéd anyanyelvi beszélői jobban értik egymást, mint a dánok és a svédek (Maurud 1976; Delsing – Åkesson 2005). Ez a jelenség az érintett nyelvek beszélői számára evidenciaszámba megy.
Sietve szögezném le, hogy véleményem szerint semmilyen csoportosításnak nem tiszte okvetlenül tükrözni a kölcsönös érthetőséget, azaz az idiómák közötti gyakorlati szintű kommunikációs átjárhatóság mértékét. Minden csoportosítás csakúgy, mint az egyes izoglosszák, azt tükrözik, hogy az egyes összehasonlítási paraméterek alapján milyen hasonlóságok és milyen különbségek fedezhetők fel az érintett idiómák között. A gond az, hogy a csoportosítások alapjául szolgáló szempontok sokszor a háttérben maradnak, így nem világos, hogy mit is kellene tükrözniük a határvonalaknak.
A lexikon szintjén aktuálisan megmutatkozó szinkrón egyezések és különbségek másfajta viszonyokra deríthetnek fényt, mint például a fonológiai különbségek. Ez természetesen a kölcsönös érthetőségre vonatkozóan is igaz. Persze ez utóbbival kapcsolatban óvatosnak kell lennünk, mivel egyetlen nyelvi szint vizsgálata nem hozhat teljességgel megbízható eredményeket. A különbségeket több nyelvi szinten kellene vizsgálni, az eredményeket pedig összegezni. De ha egyetlen szintet szeretnénk kiemelni a kölcsönös érthetőség vizsgálata tekintetében, annak a lexikon szintjének kell lennie. Jómagam eredetileg épp ezért kezdtem a lexikon szintjével foglalkozni. Később azonban be kellett látnom, hogy semmi szükség a kölcsönös érthetőség „zászlajára”. Önmagában is elegendő az a tény, hogy a lexikon szintjén történő nagyobb lexiko-etimológiai összevetések és azok mélyebb elemzései újdonságnak számítanak a számi idiómák esetében, sőt az uráli, de még az indoeurópai nyelvek esetében is van mit felfedezni az idiómák aktuálszinkrón kapcsolatainak terén. Az alapkérdés tehát az, hogy a számi idiómák lexiko-etimológiai vizsgálatai milyen eredményt hoznak, és az eredmények hogyan viszonyulnak a „klasszikus” számi idiómacsoportosításokhoz.
- A számi idiómák kvantitatív lexiko-etimológiai vizsgálata
2.1. Dialektometria
Az egyes számi idiómák közti nyelvi távolság szisztematikus mérése (dialektometria) még újdonságszámba megy. A nyelvi távolság mérése több nyelvi szinten is történhet: vizsgálhatjuk az érintett nyelvekben az egy adott fogalmat jelölő szavak fonémasorának elemenkénti egyezéseit és különbségeit, összegezve az idiómapárok eredményeit n számú vizsgált fogalom jelölői esetében (Levenshtein-távolság[4]), de a lexémák szintjén is kutathatjuk az idiómák közti egyezés mértékét, azt vizsgálva, hogy n számú fogalom esetében az egyes fogalmakat az adott idiómákban jelölő szavak milyen arányban vezethetők vissza közös etimonra. Ez utóbbi vizsgálattípusnál az adatok kezelésének és feldolgozásának számos módszere lehetséges. Felmerül például a kérdés, hogy egy adott fogalomnál idiómánként csak egy jelölőt elemzünk-e vagy pedig teret adunk az esetleges szinonimák vizsgálatának is. További kérdés lehet, hogy mit is tekintünk egyezésnek két idióma között egy adott fogalom esetében: a jelölők szótövét vetjük csak össze vagy esetleg a teljes alakot. Ez utóbbi problematika főleg az igék esetében lehet jelentős, amikor az egyes idiómák eltérő igeképző szuffixumokkal vagy különböző prefixumokkal élhetnek. Az igék esetén a szuppletivizmus további kérdéseket vethet fel: ilyenkor az igék paradigmáját különböző etimonokra visszavezethető alakok alkotják, és el kell dönteni, hogy – a szinonimák kezeléséhez hasonlóan – mindegyik szótőt bevesszük-e a vizsgálatainkba, vagy csak a főnévi igenév mint „főalak” tövét vesszük figyelembe, stb.
2.2. Håkan Rydving kutatásai
Håkan Rydving (1986, 2013) lexikai összevetéseken alapuló kutatásokat végzett, mégpedig 34 számi település nyelvi adataiból kiindulva. Arról a 34 településről és azokról az adatokról van szó, amelyek az ALE (Atlas Linguarum Europae – Európai Nyelvatlasz) kutatásaiban szerepelnek. Rydving arra a következtetésre jutott, hogy az inari számi nem olyan egyértelműen keleti számi, mint azt állítani szokás.
2.3. Saját kutatások
Amikor először végeztem lexiko-etimológiai vizsgálatokat a Swadesh-fogalmak megfelelőit kutatva hat számi idiómában, a számi nyelvjárási kontinuum gyönyörűen kirajzolódott: mindegyik vizsgált idióma a vele földrajzilag szomszédos idiómával mutatta a legnagyobb lexiko-etimológiai egyezést, és egyértelműen megmutatta a korpusz azt, amit a valóságban a számik maguk is sokszor megtapasztalnak: minél messzebb megyünk a térben, annál nagyobbakká válnak a nyelvi távolságok. De volt valami az anyagban, amit különösen izgalmasnak találtam: nevezetesen azt a tényt, hogy a vizsgált anyag alapján az északi számi és az inari számi közelebb áll egymáshoz, mint az északi számi és a lulei számi.
Én magam tehát szintén lexikai összevetéseket végeztem[5], de teljesen más korpuszok alapján és más feldolgozási módszerrel, mint Rydving. Az én főkorpuszom az érintett idiómák alapszókincséből került ki. Nyelvek teljes szókincsét lehetetlen összehasonlítani, mivel maga a „teljes szókincs” sem egy létező fogalom, másrészt pedig egy élet sem lenne elegendő egy ilyen projekt kivitelezéséhez, nyelvenként többszázezer szóval, és valószínűleg feleslegesen. Egyértelmű, hogy ki kell jelölni egy konkrét korpuszt, és erre a célra az alapszókincs egy észszerű választásnak tűnik. Többfajta alapszókincs is létezik azonban; a nyelvészet különböző területein legalább öt eltérő jelentése lehetséges e fogalomnak (Borin – Comrie – Saxena 2013: 288–289). A két legkézenfekvőbb a komparatív kutatásokhoz a következő: 1. a leggyakoribb szavak alkotta alapszókincs; 2. a történeti alapszókincs (pl. Swadesh-fogalmak), olyan fogalmak, amelyek nagyon régen jelen vannak a nyelvekben (testrészek nevei, számok stb.), és meglehetősen ellenállónak bizonyulnak a lexikai cserével szemben. Ezen alapszókincsek között lehetséges és valószínű részleges átfedés, de csak részleges, és csak kismértékű.
Az egyik legfontosabb különbség Rydving módszere és az én kutatásaim között a vizsgált korpusz és annak reprezentativitása a számi idiómákra nézve. Míg Rydving adatgyűjtő pontokról (meghatározott számi településekről) származó adatokat dolgozott fel – ahol egy település egy számi idióma helyi nyelvjárását képviseli –, addig én az általam vizsgálni kívánt idiómák egészére érvényes, vagy legalábbis az adott idiómák központi területeinek nyelvállapotát tükröző adatokat igyekeztem összegyűjteni, terepmunkával kiegészítve a szótárak anyagait.
Fontos megjegyezni, hogy természetesen a korábban már említett kilenc számi idióma egyike sem egységes, mindegyik további nyelvjárásokra illetve alnyelvjárásokra (helyi nyelvváltozatokra) tagolódik. Egyértelműen megfigyelhető egy kontinuumjelenség, nevezetesen, hogy egy adott X idiómának az egyik szomszédos Y idiómához földrajzilag közeli változatai közelebb állnak a szóban forgó szomszédos Y idiómához, mint egy másik, földrajzilag távolabbi szomszédos Z idiómához; továbbá elmondható, hogy X idióma központi területei kevesebb közös vonást mutathatnak egy szomszédos Y idiómával, mint az X idióma Y idiómához földrajzilag közeleső változatai. Megfigyelhetők olyan helyi nyelvváltozatok is, amelyekről nehéz eldönteni, melyik nagyobb idiómához is tartoznak, mivel – egy ún. interferenciazónában – átmenetet képeznek két nagyobb idiómaterület között.
2.3.1. Lexiko-etimológiai analízisek a gyakorisági alapszókincs fényében
2.3.1.1. A számi idiómák vizsgálata
Pekka Sammallahti (1998) publikálta a 845 leggyakoribb északi számi szó listáját. Ezen listáról válogattam ki a leggyakoribb és legfontosabb szófajokhoz (ige, főnév, melléknév) tartozó szavakat, szám szerint 448-at. Az adott szavak által képviselt fogalmakat jelölő szavakat összegyűjtöttem három másik számi idiómából, így összesen négy számi idiómát vizsgáltam: lulei, északi, inari és kolta. Azért ezekre az idiómákra esett a választásom, mivel az ezek közötti határvonalak a legproblémásabbak a különböző csoportosításokban.
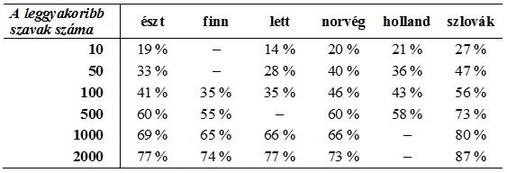
Felmerülhet a kérdés: Mire elég, mit mutathat 448 fogalom? Az 1. TÁBLÁZAT azt mutatja, hogy az egyes nyelvek leggyakoribb szavai milyen mértékben fedik le azt a szövegkorpuszt – azaz hány százalékát teszik ki annak a szövegkorpusznak –, amely alapján a szavak gyakoriságát meghatározták. A táblázatban szereplő adatok az ott említett nyelvek gyakorisági szótáraiból[6] származnak, illetve azok adatai alapján lettek kiszámolva. A 100 leggyakoribb szó 35–45%-át lefedheti a teljes szövegkorpusznak, míg az 500 leggyakoribb szó kb. 60% lefedésére képes. 500 szó felett ez az arány nem változik oly jelentős mértékben, hogy érdemes lenne bővíteni az alapszókincskorpuszt.
- TÁBLÁZAT
A nyelvenként feldolgozott szövegkorpusznak az n leggyakoribb szó általi százalékos lefedettsége az egyes nyelvekben
A kiválasztott 448 gyakori fogalmat a négy vizsgált számi idiómában képviselő szavak elemzésének eredménye azt mutatja, hogy a legnagyobb mértékű lexikai egyezés az északi számi és az inari számi között figyelhető meg, nevezetesen 90,8%. A különböző idiómapárok eredményeinek rangsora – lásd 2. TÁBLÁZAT – világosan mutatja, hogy a legtöbbször külön csoportba sorolt két idióma, azaz az északi és az inari számi mutatja egymással a legnagyobb arányú lexikai egyezést. A különbség az első és a második idiómapár között jelentős, több mint 10 százalékpont. Az északi számi – lulei számi páros áll a harmadik helyen 77,9%-kal. Ami tehát az északi számi eredményeit illeti a többi számi idiómához viszonyítva, a luleivel alkotott párosa áll a második helyen, a különbség pedig az első helyen álló északi – inari párosításhoz képest több mint 12 százalékpont.
- TÁBLÁZAT
A 448 fogalomra épülő, szógyakorisági alapú korpusz vizsgálatakor tapasztalható egyezési mutatók a négy vizsgált számi idióma körében
Ha az egyes szófajoknál külön-külön elemezzük a kapott értékeket, minden esetben hasonló végeredményt kapunk.
2.3.1.2. Referenciaanalízis egyéb uráli nyelvekkel
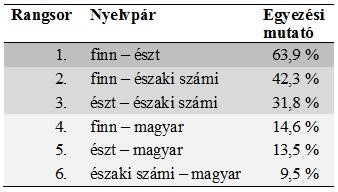
Referencia gyanánt, annak érdekében, hogy a számi idiómák eredményei összevethetők legyenek egyéb nyelvpárok eredményeivel is, hasonló lexiko-etimológiai vizsgálatokat végeztem más uráli nyelvekkel is. Megnéztem a 845 leggyakoribb szót a megbízható gyakorisági szólistával vagy szótárral rendelkező nyelvekben (északi számi, észt, finn, magyar[7]), majd kiválasztottam azokat a fogalmakat, amelyek mindegyike megtalálható a 845 leggyakoribb között az adott nyelvekben. 274 ilyen fogalmat találtam[8]. Az eredmények – lásd 3. TÁBLÁZAT – egyebek mellett azt mutatják, hogy a finn – észt páros egyezési mutatója (63,9%) a lulei és a kolta számi alkotta páros mutatójához (63,2%) hasonlítható.
- TÁBLÁZAT
A 274 fogalomra épülő, szógyakorisági alapú korpusz vizsgálatakor tapasztalható egyezési mutatók négy uráli nyelv esetében
2.3.2. Lexiko-etimológiai analízisek a történeti alapszókincs fényében
2.3.2.1. A számi idiómák vizsgálata
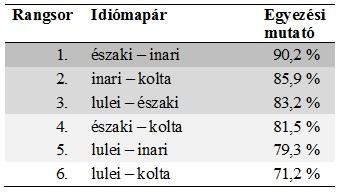
A már említett négy számi idióma egymáshoz való viszonyát a történeti alapszókincs függvényében is elemeztem 184 Swadesh-fogalom alapján[9]. Az eredmények nagyon hasonlóak a gyakoriságalapú korpusz analízisének eredményeihez – lásd 4. TÁBLÁZAT.
- TÁBLÁZAT
A 184 Swadesh-fogalomra épülő történeti alapszókincs-korpusz vizsgálatakor tapasztalható egyezési mutatók a négy vizsgált számi idióma körében
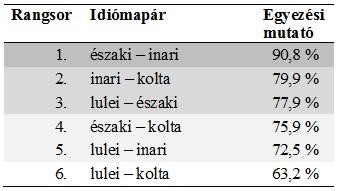
Ebben az esetben is az északi számi – inari számi páros mutatja a legnagyobb egyezést, mégpedig 90,2%-os eredménnyel (a gyakoriságalapú korpusznál ennek az idiómapárosnak 90,8% volt az egyezési mutatója, a különbség tehát elhanyagolható). A további idiómapárok helye a rangsorban szintén egybevág a másik korpusz alapján kirajzolódott eredménnyel. Az első helyen álló páros kivételével az egyezési mutatók kicsit magasabbak a történeti alapszókincs alkotta korpusz esetében, ami részint a kevesebb vizsgált fogalomnak, részint a magasabb fokú etimológiai stabilitásnak tudható be – ne feledjük, hogy az itt vizsgált Swadesh-fogalmak régóta részét képzik a számi idiómáknak.
Mint azt a 2.3.1.1. részben is említettem, felmerülhet a kérdés, hogy a vizsgált fogalmak mennyisége elegendő-e. Ez a felvetés a Swadesh-fogalmak esetében még inkább érthető, mint a gyakoriságalapú listával kapcsolatban, hiszen itt „csak” kb. 200 fogalomról van szó. April és Robert McMahon, valamint Sheila Embleton leírják, hogy 200 fogalom vizsgálata mindenképp megbízhatóbb eredménnyel jár, mint 100 fogalomé (McMahon – McMahon 2003: 24–25; Embleton 1986: 89–93), ugyanakkor azt is egyértelműen megfogalmazzák, hogy 500 fogalom vizsgálata nem mutatat jelentős különbséget egy 200-as lista eredményeihez képest (McMahon – McMahon 2005: 94–96).
2.3.2.2. Referenciaanalízis egyéb uráli nyelvekkel
A történeti alapszókincset képviselő 184 Swadesh-fogalom alapján elemeztem az északi számi és öt másik uráli nyelv viszonyát is[10]. A végeredményt az 5. TÁBLÁZAT mutatja be.
- TÁBLÁZAT
A 184 Swadesh-fogalomra épülő történeti alapszókincs-korpusz vizsgálatakor tapasztalható egyezési mutatók hat uráli nyelv esetében
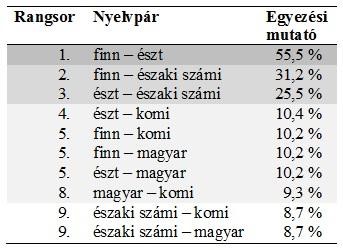
A finn – észt nyelvpár eredménye ismét a lulei számi – kolta számi idiómapár eredményéhez hasonlatos. Érdekesség, hogy az északi számi – finn nyelvpár hasonlósági mutatója mindössze 40% körüli.
2.3.3. Összegzés
A bemutatott vizsgálatok konklúziójaként elmondhatjuk, hogy a lexikai hasonlóságok alapján az inari és az északi számi áll egymáshoz a legközelebb a főbb számi idiómák között.
Nincs okvetlenül szükség új csoportosítás(ok) létrehozására, szeretném azonban kiemelni az eddig elhanyagolt lexiko-etimológiai összehasonlító kutatások jelentőségét – már csak azért is, mert mint azt láthattuk, a szokásostól eltérő kép rajzolódhat ki a lexikon szintjén végzett dialektometriai analízisek során.
Ha mindenképp szeretnénk a fentiekben vázolt kutatások alapján csoportosítani a számi idiómákat, akkor az északi számit és az inari számit mindenképp egyazon csoportba kell sorolnunk.
Szeretném leszögezni, szó sincs arról, hogy az egyéb nyelvi szinteken végzett komparatív vizsgálatoknak, illetve a különböző, régebbi idiómacsoportosításoknak ne lenne létjogosultsága. Mint azt említettem, a csoportosításokkal a fő problémát az jelenti, ha véka alá rejtjük, milyen alapokon nyugszik a nyelvváltozatok besorolása, elhallgatva ezáltal azt, hogy mit is tükröz egy adott csoportosítás. A másik fő problémát, nevezetesen a lexikon szintjének mellőzöttségét pedig már említettem.
2.4. Kitekintés – további kutatások
2.4.1. Vizsgálatok nagyobb korpusz alapján
Természetesen mindig lehet folytatni a kutatásokat, lehet újabb irányokat keresni. Jelen esetben – a fentiekben vázoltak alapján – két fő lehetőség kínálkozik: az egyik a korpusz kibővítése (több fogalomra), a másik pedig a korpusz feldolgozására vonatkozik, nevezetesen a feldolgozás során figyelembe lehetne venni az esetleges szinonimákat is, tehát nem csak egy megfelelőt rendelni egy fogalomhoz egy adott idiómában. Felmerül persze a kérdés, hogy mindez mennyiben befolyásolná az eredményeket.
Ha a nagyobb korpusszal szeretnénk dolgozni, a The Intercontinental Dictionary Series[11] egy lehetséges opció. Az IDS-projekt az 1980-as években indult azzal a céllal, hogy létrejöjjön egy olyan adatbázis, amelyben a világ minden tájáról, sok-sok nyelvből származó szólisták úgy vannak rendszerezve, hogy lehetséges legyen a lexikai szintű összevetés. A projektnek köszönhetően olyan kevéssé ismert nyelvekről is megőrizhető így információ, amelyeket a kihalás fenyeget.
Az IDS-adatbázis 1310 fogalmi egységre épül, és megengedettek egy adott nyelven belül egy adott fogalom esetében a szinonimák. Az anyag bizonyos uráli nyelveken is létezik, van például észt, finn, magyar, komi és északi számi lista is. Az adott nyelveken a fogalmak megfelelői (az ún. fordítások) vagy standard ortográfiával vagy fonetikai átírásban szerepelnek, vagy esetleg mindkét formában.
Ha megnézzük az adatbázist az interneten, különféle problémákra figyelhetünk fel. Nézzünk meg ezek közül néhányat.
Némely angol címszó (azaz a megadott fogalom) pontatlanul van megfogalmazva: a magyarázatképpen illetve pontosításképpen esetlegesen megadott szinonimák több esetben jelentősen különböző fogalmakat takarnak, félrevezetve így a fordítókat, akik más nyelveken létrehoznák az adatbázist, és félrevezetik az adott nyelveket nem beszélő felhasználókat is, mivel nem világos, hogy ezekben az esetekben a fordítások mely fogalmat takarják. Álljon itt erre három példa: 1. spring, well; 2. vein, artery; 3. river, stream, brook.
Egyes nyelveken az egyes fordítások összehasonlíthatatlanok más nyelvekre történt fordításokkal, mivel igazából eltérő fogalmakat takarnak. Erre jó példa az angol boar címszó, amely jelentése lehet ’kan disznó’ és ’vaddisznó’ is, és e poliszémia okán fordulhat elő az, hogy a boar címszónak az IDS-adatbázisban szereplő megfelelői az egyes uráli nyelveken nem vethetők össze egymással: észt kult (’kan disznó’), finn karju (’kan disznó’), komi вöpпopcь (’vaddisznó’), magyar vaddisznó.
Érthetetlen okokból teljesen hibás fordításokra is van példa: angol cockroach ≠ magyar porosz (!), a helyes fordítás csótány vagy svábbogár lenne; angol beget (of father) ≠ magyar születik, a helyes fordítás nemz lenne; angol be born ≠ magyar szül, a helyes fordítás születik lenne.
Gyakoriak a különféle elírások, helyesírási hibák. Néhány magyar példa: ásít helyett císít, küzd helyett küzöl, bárd helyett bárcl, elítél helyett elétel. Az ilyen és ehhez hasonló hibák alapján úgy tűnik, mintha egy magyarul nem tudó munkatárs kézirat alapján vitte volna be az adatokat.
A magyar fordításoknál gyakori hiba a fonetikai átírás és a standard ortográfia keveredése egy szón belül. Például tajték helyett tayték, család helyett czalád.
Erősen megkérdőjelezhető, hogy egyes fogalmak vizsgálata szükséges-e az uráli (és egyéb) nyelvcsaládhoz tartozó nyelvek esetében. Néhány példa: parrot; porpoise, dolphin; whale; elephant; camel; crocodile, alligator; chili pepper; poncho; grass-skirt; banana tree; banyan; sweet potato; yam; tapioca, manioc, cassava.
Ezen problémákat félretéve – és az észlelt hibák javítása után – végeztem egy lexiko-etimológiai analízist 1310 helyett 1250 fogalmat vizsgálva öt olyan uráli nyelvben, amelyek a korábbi kutatásaimban is szerepeltek (északi számi, észt, finn, komi, magyar). Csak azokat a fogalmakat mellőztem, ahol valamely nyelv esetében valamiért hiányzott a fordítás. Ezen kívül több esetben módosítottam a magyar fordítást. Az eredményeket a 6. TÁBLÁZAT foglalja össze.
- TÁBLÁZAT
Az 1250 IDS-fogalomra épülő korpusz vizsgálatakor tapasztalható egyezési mutatók öt uráli nyelv esetében
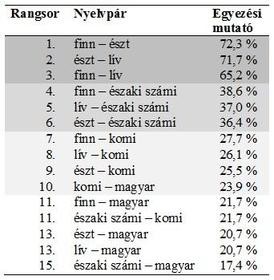
A nyelvpárok egyezési mutató szerinti rangsorolása tekintetében az eredmények egyértelmű hasonlóságot mutatnak a 274 fogalommal vizsgált gyakoriságalapú korpusz, valamint a 184 fogalommal vizsgált, történeti alapszókincset tükröző korpusz eredményeivel. A mutatók százalékértékei természetesen alacsonyabbak a nagyobb korpusz esetében.
Az IDS-korpusz fogalmait megvizsgálhatnánk több számi idiómában is, de létrehozhatunk egy saját nagy korpuszt is, kb. 1000 fogalommal. Ez utóbbi talán célravezetőbb lenne, már csak azért is, mert – mint azt a fentiekben is említettem – számos IDS-fogalomnak erősen megkérdőjelezhető a létjogosultsága az uráli nyelvek (és így a számi idiómák) lexiko-etimológiai vizsgálataiban.
2.4.2. Településenkénti számi adatgyűjtés
A nemzetközi dialektometriai szakirodalomban leírt, különösen a salzburgi dialektometriai iskola[12] módszereivel végzett kutatások alapján felmerülhetne egy számi adatgyűjtőpont-hálózat kiépítésének a gondolata. Egy ilyen hálózatban végzett adatgyűjtő munka révén létrehozható lenne egy számi nyelvjárási atlasz, illetve a számi idiómák közti viszonyt is behatóbban lehetne vizsgálni a helyi nyelvjárások szintjén megmutatkozó hasonlóságok és különbségek összegzéséből következtetve. Sajnos azonban egy ilyen hálózat kiépítése Számiföldön ma már majdhogynem lehetetlen. Nem kifejezetten számispecifikus problémáról van szó. Európa számos országában egyre nehezebb feladat a régi nyelvatlaszok aktualizálása, mivel az emberek egyre könnyebben és egyre gyakrabban váltanak lakhelyet, és költöznek el akár több száz kilométerrel odébb. Így a helyi nyelvjárások gyakran eltűnnek, a költözők által eredetileg beszélt helyi nyelvjárás (tkp. a beszélők eredeti idiolektusa) pedig vagy a „köznyelvvel” keveredik (a számikkal kapcsolatban ilyenről természetesen nincs szó), vagy azzal a helyi dialektussal, amely az új lakhelyükön használatos. A számik esetében a költözés szintén gyakorivá vált, és például az a település, ahol ma a legtöbb déli számi beszélőt találhatjuk, nem más, mint Stockholm. Emellett persze meg lehetne említeni sok más olyan tényezőt is, amely valamilyen módon a nyelvjárások „ellen” dolgozik az utóbbi évtizedekben – elég, ha csak a telekommunikáció rohamos fejlődésére gondolunk.
- Konklúzió
Az egyes számi idiómák körében végzett komparatív lexiko-etimológiai kutatások egyértelműen azt támasztják alá, hogy a lexikon szintjén az északi számi és az inari számi mutatja a legnagyobb hasonlóságot a vizsgált (a csoportosítások alapján problémás) számi idiómák között. A vázolt kutatások alapján elmondható, hogy a lexikon fényében nem indokolt az északi és az inari számi közé markáns határvonalat húzni és e két idiómát két külön csoportba sorolni.
A lexiko-etimológiai és dialektometriai vizsgálatoknak nem célja a korábbi kutatási eredményeket és csoportosításokat helyettesíteni, azokat devalválni, sokkal inkább azokat kiegészíteni. A fő cél az, hogy felhívjuk a figyelmet a lexikon szintjének elhanyagolt mivoltára, illetve jelentőségére.
A kutatások folytatásaként a vizsgált korpuszok kibővíthetők. A kutatásokat ki lehet terjeszteni további számi idiómákra, illetve esetlegesen helyi nyelvjárásokra is, amennyiben biztosított a megbízható adatforrás.
Bibliográfia
Barðdal, Jóhanna – Jörgensen, Nils – Larsen, gorm – Martinussen, Bente
1997 Nordiska. Våra språk förr och nu. Lund.
Bergsland, Knut
1946 Røros-lappisk grammatikk. Oslo.
1968 The Grouping of Lapp Dialects as a Problem of Historical Linguistics. In Congressus Secundus Internationalis Fenno-Ugristarum, I. Helsinki.
Bergsland, Knut – Vogt, Hans
1962 On the Validity of Glottochronology. In Current Anthropology 3, No. 2, 115–153.
BORIN, Lars – COMRIE, Bernard – SAXENA, Anju
2013 The Intercontinental Dictionary Series – a rich and principled database for language comparison. In Lars Borin – Anju Saxena (eds.): Approaches to Measuring Linguistic Differences, 285–302. Berlin.
Bussmann, Hadumod
2002 Lexikon der Sprachwissenschaft. Stuttgart.
Collinder, Björn
1949 The Lapps. Princeton.
1953 Lapparna. En bok om samefolkets forntid och nutid. Stockholm.
Delsing, Lars-Olof – Lundin Åkesson, Katarina
2005 Håller språket ihop Norden? : en forskningsrapport om ungdomars förståelse av danska, norska och svenska. Köpenhamn.
EMBLETON, Sheila M.
1986 Statistics in Historical Linguistics. Bochum.
FERNANDEZ, M. M. Jocelyne
1997 Parlons lapon. Paris.
FRÖBERG, Paul
1967 Stil. Översikt av språkutveckling, stilarter, diktarter och versformer. Stockholm.
GINSBURGH, Victor – Weber, Shlomo
2011 How Many Languages Do We Need? The Economics of Linguistic Diversity. Princeton–Oxford.
GOEBL, Hans
2011 Introduction aux problèmes et méthodes de l’« École dialectométrique de Salzbourg » (avec des exemples gallo-, italo- et ibéroromans). In Álvarez Pérez – Xosé Afonso – Ernestina Carrilho – Catarina Magro (eds.): Proceedings of the International Symposium on Limits and Areas in Dialectology (LimiAr),117–166. Lisbon.
GUDSCHINSKY, Sarah C.
1956 Three Disturbing Questions concerning Lexicostatistics. International Journal of American Linguistics 22, 212–213.
HANSEGÅRD, Nils-Erik
2000 Dialekt eller språk? Om de västsamiska och norrbottensfinska skriftspråken. Uppsala.
HEERINGA, Wilbert
2004 Measuring Dialect Pronunciation Differences using Levenshtein Distance. Groningen Dissertations in Linguistics 46. Groningen.
HEGGSTAD, Kolbjørn
1982 Norsk frekvensordbok. De 10000 vanligste ord fra norske aviser. Bergen.
HELIMSZKIJ, Jevgenyij Arnoldovics = Хелимcкий, Евгений Арнольдович
1982 Древнейшие венгерско-самодийские языковые параллели. Лингвистическая и этногенетическая интерпретация. Mocквa.
HOIJER, Harry
1956 Lexicostatistics: A Critique. Language 32, 49–60.
JAKUBAITE, Tamāra – GUļEvska, Dainuvīte – Ozola, Vera – Prūse, Rudīte – RUBINA, Aina – Sika, Nira
1969 Latviešu valodas biežuma vārdnīca. 2. sējumā. [2. kötet; 1–4. kötet: 1966–1976] Rīga.
KAALEP, Heiki-Jaan – Muischnek, Kadri
2002 Eesti kirjakeele sagedussõnastik. Tartu.
KORHONEN, Mikko
1981 Samiska dialekter. [Az Uppsalai Egyetem egyetemi jegyzete, a „Lapin murteiden keskinäisistä suhteista” című írás svéd fordítása. A finn eredeti megjelent: Lapin tutkimusseuran vuosikirja V (1964).] Uppsala.
KROEBER, Alfred L.
1955 Linguistic Time Depth Results so Far and Their Meaning. International Journal of American Linguistics 21 (2), 91–104.
LEHTIRANTA, Juhani
1982 Eine Beobachtung über die Gründe der raschen Veränderung des Grundwortschatzes im Lappischen. Finnisch-ugrische Forschungen 44, 114–119.
MAURUD, Øivind
1976 Nabospråkforståelse i Skandinavia. Stockholm.
MCMAHON, April – McMahon, Robert
2003 Finding Families: Quantitative Methods in Language Classification. Transactions of the Philological Society 101, 7–55.
2005 Language Classification by Numbers. Oxford.
MISTRÍK, Jozef
1969 Frekvencia slov v slovenčine. Bratislava.
RAUN, Alo
1957 Über die sogenannte lexikostatistische Methode oder Glottochronologie und ihre Anwendung auf das Finnisch-Ugrische und Türkische. Ural-Altaische Jahrbücher 29, 151–154.
REA, John A.
1958 Concerning the Validity of Lexicostatistics. International Journal of American Linguistics 24, 145–150.
1973 The Romance Data of the Pilot Studies for Glottochronology. In T. A. Sebeok (ed.): Diachronic, Areal and Typological Linguistics, 355–367. The Hague.
1990 Lexicostatistics. In Edgar Polomé (ed.): Research Guide on Language Change, 217–222. Berlin.
RYDVING, Håkan
1986 Hecкoлькo зaмeчaний o peзyльтaтax иccлeдoвaния caaмcкoй диaлeктoлoгии в пpeдaлax ЛAE. Coвeтcкoe Финнo-Угpoвeдeниe 22, 198–202.
2013 Words and Varieties. Lexical Variation in Saami. Mémoires de la Société Finno-Ougrienne 269. Helsinki, Suomalais-Ugrilainen Seura.
SAMMALLAHTI, Pekka
1985 Die Definition von Sprachgrenzen in einem Kontinuum von Dialekten: Die lappischen Sprachen und einige Grundfragen der dialektologie. In Wolfgang Veenker (ed.): Dialectologia Uralica, Materialen des ersten Internationalen Symposions zur Dialektologie der uralischen Sprachen 4.–7. September 1984 in Hamburg (Veröffentlichungen der Societas Uralo-Altaica, Band 20), 149–158. Wiesbaden.
1998 The Saami Languages. An Introduction. Kárášjohka.
SAUKKONEN, Pauli – Haipus, Marjatta – Niemikorpi, Antero – Sulkala, Helena
1979 Suomen kielen taajuussanasto. A Frequency Dictionary of Finnish. Porvo–Helsinki–Juva.
SWADESH, Morris
1950 Salish Internal Relationships. International Journal of American Linguistics 16, 157–167.
1952 Lexico-Statistic Dating of Prehistoric Ethnic Contacts. Proceedings of the American Philosophical Society 96, 452–463.
1955 Towards Greater Accuracy in Lexicostatistic Dating. International Journal of American Linguistics 21, 121–137.
TILLINGER Gábor
2009 Les limites des langues sames : Nouvelles méthodes de la classification des langues et des dialectes – avec l’exemple de certaines langues finno-ougriennes, scandinaves et romanes. In Kajsa Andersson (ed.): L’image du Sápmi. Études comparées. Humanistica Oerebroensia, Artes et linguae, nr. 15. Örebro, Örebro universitet, 460–478.
2013 Langues, dialectes et patois – Problèmes de terminologie dialectologique. Réflexions sur la situation géolinguistique en France et la terminologie française. Argumentum 9, Debrecen, Debreceni Egyetemi Kiadó, 1–18.
2014 Samiska ord för ord. Att mäta lexikalt avstånd mellan språk. Studia Uralica Upsaliensia 39, Acta Universitatis Upsaliensis. Uppsala, Uppsala universitet.
2015 Entre oïl, oc et francoprovençal. Différences lexicales dans la zone d’interférence appelée « Croissant » d’après les atlas linguistiques de la France. Studia Romanica de Debrecen, Series Linguistica, Fasc. XI. Debrecen, Université de Debrecen.
UIT DEN BOOGAART, Piet C.
1975 Woordfrequenties in geschreven en gesproken Nederlands. Utrecht.
VIITSO, Tiit-Rein
1997 Keelesugulus ja soome-ugri keelepuu. Akadeemia 5, 899–929.
Tillinger Gábor
[1] A számi esetében az elmúlt évtizedekben rendszeresen felmerül a kérdés, hogy egy számi nyelvről és annak nyelvjárásairól, vagy inkább több számi nyelvről és azok dialektusairól helytállóbb-e beszélnünk (lásd például Collinder 1949: 2; Sammallahti 1985: 149; Hansegård 2000). Én most nem kívánok ebben a kérdésben állást foglalni, így a semleges idióma terminussal illetem a számi nyelvváltozatokat. A nyelv kontra nyelvjárás problematikája egyébként inkább politikai, mintsem nyelvészeti kérdés. Nyelvészeti szempontból az egyes nyelvváltozatok egymáshoz viszonyított szintbesorolása sokkal lényegesebb, mint az adott szintekre alkalmazott terminus (Tillinger 2013; 2014: 18–23; 2015: 11–34).
[2] Az akkalai számi már kihaltnak tekinthető.
[3] A norvég nyelv esetében egyesek elkülönítik a bokmål és a nynorsk változatokat az északi germán nyelvek felosztásakor, a keleti csoporthoz sorolva a bokmålt, a nynorskot pedig a nyugatihoz (Fröberg 1967: 96; Ginsburgh – Weber 2011: 42).
[4] Lásd például Heeringa 2004.
[5] A módszer alapelveiről és a korpusz összeállításának szempontjairól részletesen lásd Tillinger 2014, illetve kevésbé részletesen Tillinger 2009: 464–473. Lényeges hangsúlyozni, hogy a fogalomlisták alapján az egyes fogalmakhoz a vizsgált idiómákban tartozó jelölők (szavak) kiválasztásának irányelvei jelentős eltéréseket mutathatnak kutatásonként és főleg kutatónként. Véleményem szerint kiemelkedően fontos, hogy az itt is leírt komparatív vizsgálatokhoz saját szólisták készüljenek, a kutatást végzők saját szempontjai alapján.
[6] észt: Kaalep – Muischnek 2002
finn: Saukkonen – Haipus – Niemikorpi – Sulkala 1979
lett: Jakubaite – Guļevska – Ozola – Prūse – Rubina – Sika 1969
norvég: Heggstad 1982
holland: Uit den Boogaart 1975
szlovák: Mistrík 1969
[7] A felhasznált magyar gyakorisági szótár: Füredi – Kelemen 1989; a többi vizsgált uráli nyelv gyakorisági szótárára, illetve az északi számi gyakorisági szólistára fentebb már utaltunk.
[8] További lehetőség lett volna, ha nem csak a közös fogalmakból állítom össze a korpuszt. Egy bővebb korpusz lexiko-etimológiai vizsgálata részét képzi a jövőbeni kutatási terveimnek.
[9] Morris Swadesh fogalomlistái eredetileg glottokronológiai vizsgálatokhoz készültek. A glottokronológia módszerét sokan kritizálták, és egyértelműen megbukott (lásd például Kroeber 1955; Gudschinsky 1956; Hoijer 1956; Rea 1958, 1973, 1990; Bergsland & Vogt 1962). A Swadesh-listák fogalmai ugyanakkor elég jó keresztmetszetét nyújtják a történeti alapszókincsnek, így egyéb nyelvészeti összevetésekhez megfelelő kiindulópontok lehetnek. Swadesh készített egy 215, egy 200, majd később egy 100 fogalomból álló listát is (Swadesh 1950; 1952: 456; 1955: 124). A rövidebb listákon szerepel néhány olyan fogalom is, amely az eredeti, 215 fogalmat tartalmazó listán nem szerepelt, így összesen 224 Swadesh-fogalommal számolhatunk. Swadesh a fogalmakat angol szavak formájában adta meg, amelyek megfelelőit nem minden fogalom esetében lehetséges egyértelműen meghatározni a számi idiómákban. Ez az oka annak, hogy 40 fogalmat mellőztem a kutatásaimban, így épült végül a korpusz 184 Swadesh-fogalomra. A korpusz természetesen saját összeállítású, a szólisták összeállítási elveiről részletesen lásd Tillinger 2014.
[10] Egyes uráli nyelvek Swadesh-fogalmak alapján mutatott lexikai egyezéseit korábban már más kutatók is vizsgálták, lásd például Raun 1957: 152–153; Lehtiranta 1982: 114; Helimszkij 1982: 11; Viitso 1997: 915. A publikált eredmények több esetben markáns eltéréseket tartalmaznak. Mivel az adott szólistákat nem tették közzé a számadatok mellett, és nem is részletezik a listák összeállításának alapelveit, a publikált számadatok nem építhetők be további kutatásokba, csak referenciaként lehet hivatkozni rájuk. Ráadásul többször is előfordul, hogy valaki (rejtett/véletlen) módosításokkal hivatkozik mások számadataira. A fentiekkel kapcsolatban lásd Tillinger 2014: 82–84.
[11] http://ids.clld.org
[12] Lásd például Goebl 2011.